In this blog we explore the sorting performance of Spark/Crail on a 100Gbit/s RDMA cluster. Sorting large data sets efficiently on a cluster is particularly interesting from a network perspective as most of the input data will have to cross the network at least once. Hence, a sorting workload should be an ideal candidate to be accelerated by a fast network.
The following table summarizes the results of this blog and provides a comparison with other sorting benchmarks. In essence, Spark/Crail is sorting 12.8 TB of data in 98 seconds, which calculates to a sorting rate of 3.13 GB/min/core. This is about a factor of 5 faster than the sorting performance of the Spark 2014 benchmark winner, and only about 28% slower than the 2016 winner of the sorting benchmark -- a sorting benchmark running native code optimized specifically for sorting.
| Spark/Crail | Spark/Vanilla | Spark/Winner2014 | Tencent/Winner2016 | |
|---|---|---|---|---|
| Data Size | 12.8 TB | 12.8 TB | 100 TB | 100 TB |
| Elapsed Time | 98 s | 527 s | 1406 s | 98.8 s |
| Cores | 2560 | 2560 | 6592 | 10240 |
| Nodes | 128 | 128 | 206 | 512 |
| Network | 100 Gbit/s | 100 Gbit/s | 10 Gbit/s | 100 Gbit/s |
| Sorting rate | 7.8 TB/min | 1.4 TB/min | 4.27 TB/min | 44.78 TB/min |
| Sorting rate/core | 3.13 GB/min | 0.58 GB/min | 0.66 GB/min | 4.4 GB/min |
Hardware Configuration
The specific cluster configuration used for the experiments in this blog:
- Cluster
- 128 node OpenPower cluster
- Node configuration
- CPU: 2x OpenPOWER Power8 10-core @2.9Ghz
- DRAM: 512GB DDR4
- Storage: 4x Huawei ES3600P V3 1.2TB NVMe SSD
- Network: 100Gbit/s Ethernet Mellanox ConnectX-4 EN (RoCE)
- Software
- Ubuntu 16.04 with Linux kernel version 4.4.0-31
- Spark 2.0.0
- Crail 1.0 (Crail only used during shuffle, input/output is on HDFS)
Anatomy Spark Sorting
A Spark sorting job consists of two phases. The first phase is a mapping or classification phase - where individual workers read their part of the key-value (KV) input data and classify the KV pairs based on their keys. This phase involves only very little networking as most of the workers run locally on the nodes that host the HDFS data blocks. During the second so called reduce phase, each worker collects all KV pairs for a particular key range from all the workers, de-serializes the data and sorts the resulting objects. This pipeline runs on all cores in multiple waves of tasks on all the compute nodes in the cluster. Naturally, the performance of such a pipeline depends upon both the network as well as the CPU performance, which together should dictate the overall job run time.
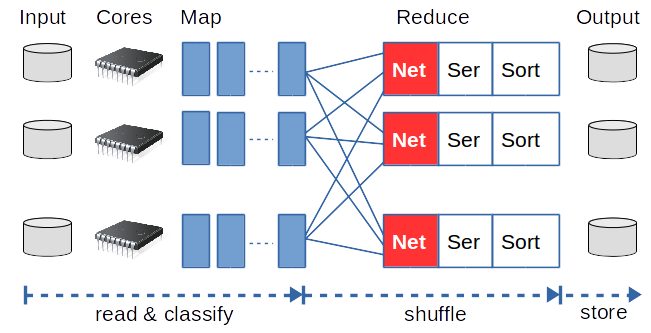
Using Vanilla Spark
The first question we are interested in is to what extent such a sorting benchmark can drive the 100Gbit/s network fabric. Making good use of the network is important since a reduce task needs to first fetch all the relevant data from the network before it can start sorting the data. Unfortunately, it turns out that when running vanilla Spark on the cluster, the network usage stays at only 5-10%.

The poor network usage matches with the general observation we made in our previous HotCloud'16 publication where we show that a faster network does not necessarily lead to a better runtime. The problem can be understood by looking at a single reduce task in the sorting benchmark. While the actual time for fetching all the data over the network decreases with increasing network bandwidth, the time a reduce task spends on funneling the data through the stack, deserializing and sorting it outweighs the transmission time by far. The figure below shows percentage wise for different network technologies, how much time a reduce task spends on waiting for data versus executing CPU instructions (a more detailed breakdown of the time can be found in the paper). Clearly, in such a situation, a higher network bandwidth will only improve the increasinlgy small red part and, and thus, will not result in a substantial runtime reduction.

Consequently, to improve the runtime of the sorting benchmark and to make good use of the 100Gbit/s network, the number of CPU instructions executed per byte transferred need to be reduced massively. In the following, we show how we use the Crail shuffle engine to cut down the software overheads related to networking, deserialization and sorting and thereby empower the reduce tasks in the sorting benchmark to consume data at a speed that is very close to the network limit (~70Gbit/s all-to-all).
Using the Crail Shuffler
An overview of the Crail shuffler is provided in the documentation section. The main difference between the Crail shuffler and the Spark built-in shuffler lies in the way data from the network is processed in a reduce task. The Spark shuffler is based on TCP sockets, thus, many CPU instructions are necessary to bring the data from the networking interface to the buffer inside Spark. In contrast, the Crail shuffler shares shuffle data through the Crail file system, and therefore data is transferred directly via DMA from the network interface to the Spark shuffle buffer within the JVM.
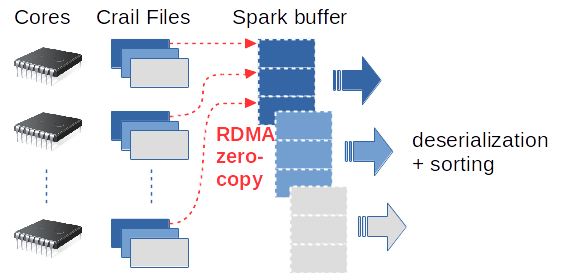
During the map phase, the Crail shuffler organizes each key range in a set of Crail files, one file per Spark core per key range. Reading the shuffle data from the Crail file system in the reduce phase not only eliminates data copies and avoids system calls, it also makes sure the different segments (files) are placed at the right offset within the reduce buffer to create one contiguous memory area that can immediately be used for deserialization and sorting.
As illustrated in the documentation section, the Crail shuffler allows applications to use their own custom serializer and sorter. The recommended serializer for Spark is Kryo, which is a generic serializer. Being generic, however, comes at a cost. Specifically, Kryo requires more type information to be stored along with the serialized data than a custom serializer would need, and also the parsing is more complex for a generic serializer. On top of this, Kryo also comes with its own buffering, introducing additional memory copies. In our benchmark, we use a custom serializer that takes advantage of the fact that the data consists of fixed size key/value pairs. The custom serializer further avoids extra buffering and directly interfaces with Crail file system streams when reading and writing data.
As with serialization, the Spark built-in sorter is a general purpose TimSort that can sort arbitrary collections of comparable objects. In our benchmark, we instruct the Crail shuffler to use a Radix sorter instead. The Radix sorter cannot be applied to arbitrary objects but works well for keys of a fixed byte length. The standard pipeline of a reduce task is to first deserialize the data and then sort it. In the particular configuration of the Crail shuffler, we turn these two steps around and first sort the data and deserialize it later. This is possible because the data is read into a contiguous off-heap buffer that can be sorted almost in-place.
Spark/Crail Sorting Performance
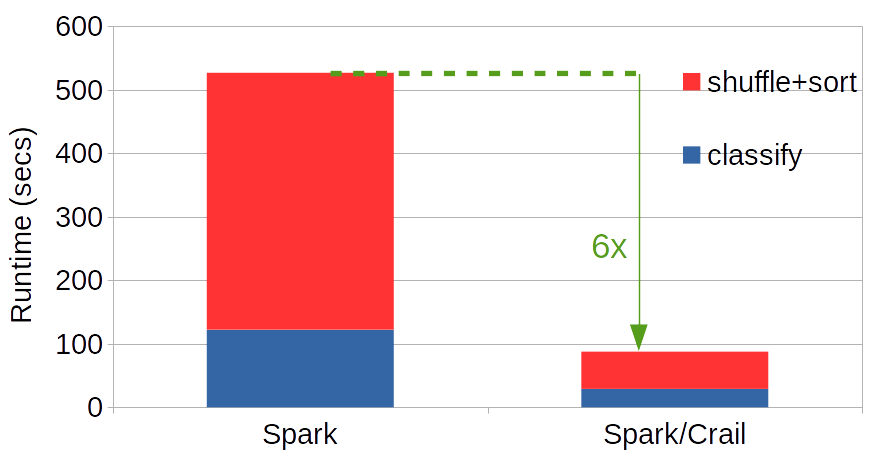
The figure below shows the overall performance of Spark/Crail vs Spark/Vanilla on a 12.8 TB data set. With a cluster size of 128 nodes, each node gets to sort 100GB of data - if the data distribution is uniform. As can be seen, using the Crail shuffler, the total job runtime is reduced by a factor of 6. Most of the gains come from the reduce side, which is where the networking takes place. However, the map phase is also faster which comes from the more efficient serialization but also from a faster I/O. The built-in Spark shuffler dumps data into files absorbed by the buffer cache (no disk writes took place during shuffle), which requires file system calls and data copies. The Crail shuffler instead uses memory mapped I/O to write local Crail files, avoiding both data copies, system calls and kernel context switches.
One key question of interest is about the network usage of the Crail shuffler during the sorting benchmark. In the figure below, we show the data rate at which the different reduce tasks fetch data from the network. Each point in the figure corresponds to one reduce task. In our configuration, we run 3 Spark executors per node and 5 Spark cores per executor. Thus, 1920 reduce tasks are running concurrently (out of 6400 reduce tasks in total) generating a cluster-wide all-to-all traffic of about 70Gbit/s per node during that phase.

In this blog post, we have shown that Crail successfully manages to translate the raw network performance into actual workload level gains. The exercise with TeraSort as an application validates the design decisions we made in Crail. Stay tuned for more results with different workloads and hardware configurations.
How to run Sorting with Spark/Crail
All the components required to run the sorting benchmark using Spark/Crail are open source. Here is some guidance how to run the benchmark:
- Build and deploy Crail using the instructions at documentation
- Enable the Crail shuffler for Spark by building Spark-IO using the instructions at documentation
- Configure the DRAM storage tier of Crail so that all the shuffle data fits into the DRAM tier.
- Build the sorting benchmark using the instructions on GitHub
- Make sure you have the custom serializer and sorter specified in spark-defaults.conf
- Run Hadoop TeraGen to produce a valid data set. We used standard HDFS for both input and output data.
- Run the Crail-TeraSort on your Spark cluster. The command line we have used on the 128 node cluster is the following:
./bin/spark-submit -v --num-executors 384 --executor-cores 5 --executor-memory 64G
--driver-memory 64G --master yarn
--class com.ibm.crail.terasort.TeraSort path/to/crail-terasort-2.0.jar
-i /terasort-input-1280g -o /terasort-output-1280g
Have questions or comments? Feel free to open an issue here